Terror on the Strip: Building Event Timelines with Python and GDELT
October 15, 2017

Source: http://news3lv.com/, file
It all started a few minutes after 10 pm on October 1st.
The gunshots sounded like firecrackers at first. People in the crowd didn't understand what was happening when the band stopped playing and Jason Aldean hustled off stage.
"That's gunshots," a man said on a cellphone video in the nearly half-minute of silence and confusion that followed. Then the pop-pop-pop noise resumed. And pure terror set in.
For reasons that remain unknown, Stephen Paddock, a 64-year old white male, fired on a crowd of 22,000 for 10 minutes unhindered in 40- to 50-round bursts from his 32nd floor room of the Mandalay Bay Hotel and Casino. Paddock had at least 20 guns and hundreds of rounds of ammunition — some with scopes — in his hotel room, and busted out windows with a hammer-like object to create his sniper's perch roughly hundreds of yards from the Route 91 Harvest Festival of country music. Analysis of the shooting video showed Paddock fired a staggering 280 rounds in one 31-second span.

Source: David Becker/Getty Images
While some concertgoers hit the ground, others forced their way to the crowded exits, shoving through narrow gates, trampling one another, and climbing over fences. They had little cover and no easy way to escape. Those who were not hurt hid behind concession stands or crawled under parked cars. The scene was pure chaos. Bodies were lying on the artificial turf installed in front of the stage, and people were screaming and crying. The sound of people running on the bleachers added to the confusion, leading some of the people still present to suspect the concert was being invaded with multiple shooters.
At 10:14 p.m., an officer said on his radio that he was pinned down against a wall on Las Vegas Boulevard with 40 to 50 people."We can't worry about the victims," an officer said at 10:15 p.m. "We need to stop the shooter before we have more victims. Anybody have eyes on him ... stop the shooter."
Police frantically tried to locate the shooter and determine whether the gunfire was coming from Mandalay Bay or the neighboring Luxor hotel. Every second was precious. Any time wasted looking in the wrong hotel resulted in more time to reload and unleash a volley of bullets on the terrified crowd below.

Source: John Locher/AP Photo
Code/Tutorial Introduction
Horrible flash-in-the-pan events, such as the Las Vegas active shooter crisis, happen infrequently in specific cities. However, when looking at destabilizing events on a national or global scale, we learn that these types of events are a regular occurrence. In the past, getting information on these events depended on the location of the event, your proximity to the event, and the likelihood of a news provider in your region (and language) covering the event. But the arrival of the information age has made it possible to learn about these events in real time regardless of location. Services such as Global Database of Events, Language, and Tone (GDELT) track these events in remote locations across the globe.
This tutorial shows how the mining of auto-parsed news stories can keep you (or your client) informed of the evolving security situation in a place of interest. Included is a short introduction to a python client I built to access and wrangle parsed news stories using GDELT. By the end of this tutorial, you will have the tools needed to build a timeline of events using Python and gdeltPyR. More importantly, these techniques will help you create narratives from news stories written in over 100 languages using GDELT’s translated events table. For others considering writing a tutorial, try the narrative format we will use for this post. Data scientists and data engineers need to be well-versed in the art of writing and narratives provide great practice! You can download the notebook for this tutorial here.
Understanding the Narrative Tutorial Format
This tutorial is split into sections. We switch from a narrative story section, told using the data returned from gdeltPyR and a tutorial section that gives instruction on how to use gdeltPyR and analyze the returned data. I use a page splitter and different font to signal the switch between a narrative and coding section.
Every fact and image in the narrative came from news stories accessed via gdeltPyR. Using data wrangling and time series analysis techniques, we will order the stories chronologically to see how this active shooter event evolved in time. Moreover, we understand just how responsive the GDELT service is. Nearly one hour after the first gunshots were fired, GDELT had automatically geolocated this event to Las Vegas and catalogued it as a crisis involving firearms. The first GDELT report came at 23:15 PDT (06:15 in UTC time). News reports suggest the shooting started at 22:08 PDT (05:08 UTC)! We can even use time series analysis to build an alert for a city and specific type of event using GDELT data.
It cannot go unnoticed that the example I present in this tutorial is very simple. However, GDELT offers more data sets that support higher orders of analysis. Data sets that are (or will be) available via gdeltPyR include:
- Coming Soon GDELT Visual Global Knowledge Graph (VGKG) - Access millions of images tied to news stories; includes metadata tags and other fields for higher order analysis of images, topics, and global news media
- Coming Soon American Television Global Knowledge Graph (TV-GKG) - programmatic access to metadata of parsed closed captioning covering more than 150 English language American television stations in 20 markets, some dating as far back as June 2009. Metadata and tags support higher order analysis
- Available Global Knowledge Graph (GKG) - parsed feed that links every person, organization, location, count, theme, news source, and event mentioned in news articles published worldwide into a single network
- Coming Soon GDELT GEO 2.0 API- map the geography of keyword based worldwide news using a keyword filter; updates every 15 minutes.
- Available Event mentions - table that records every mention of an event over time, along with the timestamp the article was published
- Available Events Database - catalog of worldwide activities (“events”) in over 300 categories from protests and military attacks to peace appeals and diplomatic exchanges. Each event record details 58 fields capturing different attributes of the event; machine translation coverage of all monitored content in 65 core languages, with a sample of an additional 35 languages hand translated.
As you can see, GDELT is a powerful data set. But, what exactly is GDELT? Let’s run through an introduction.
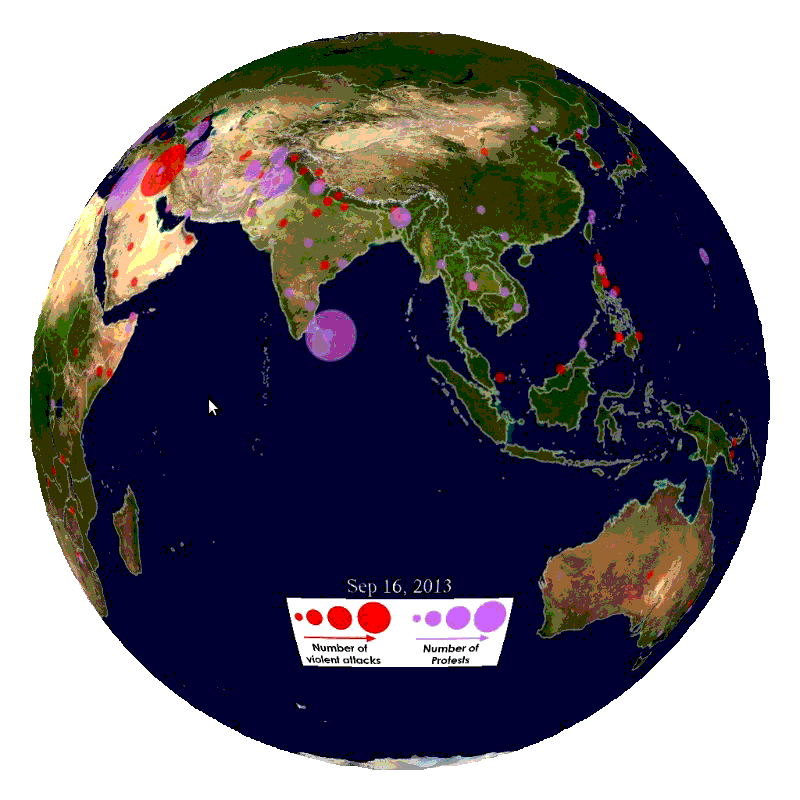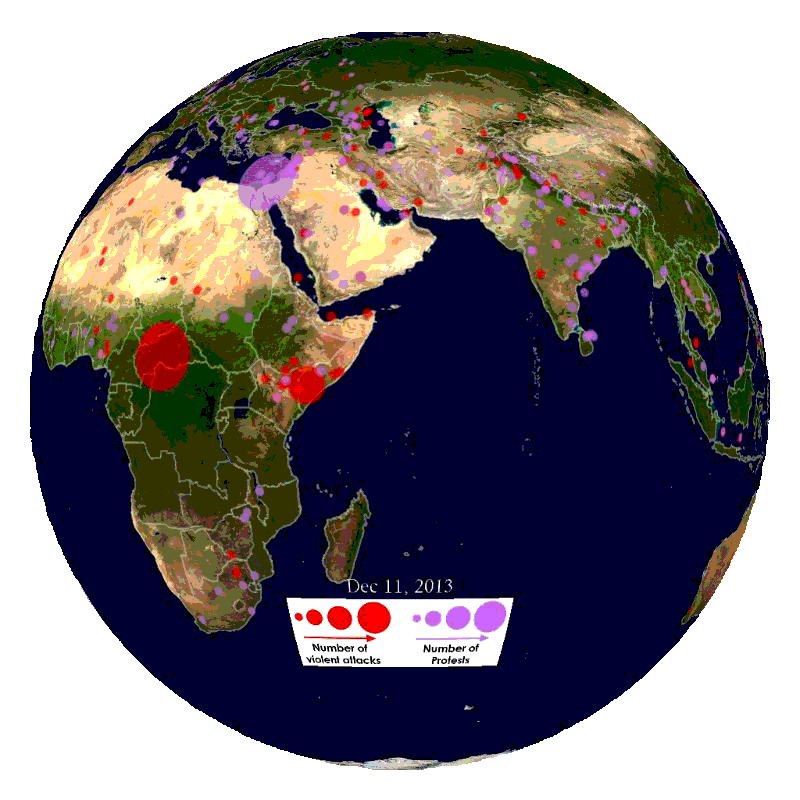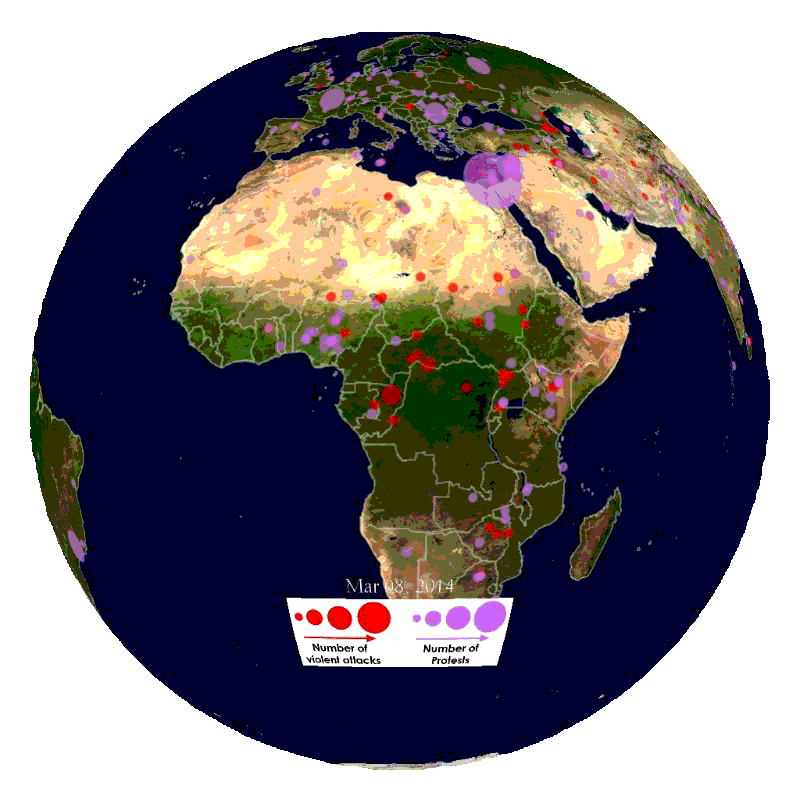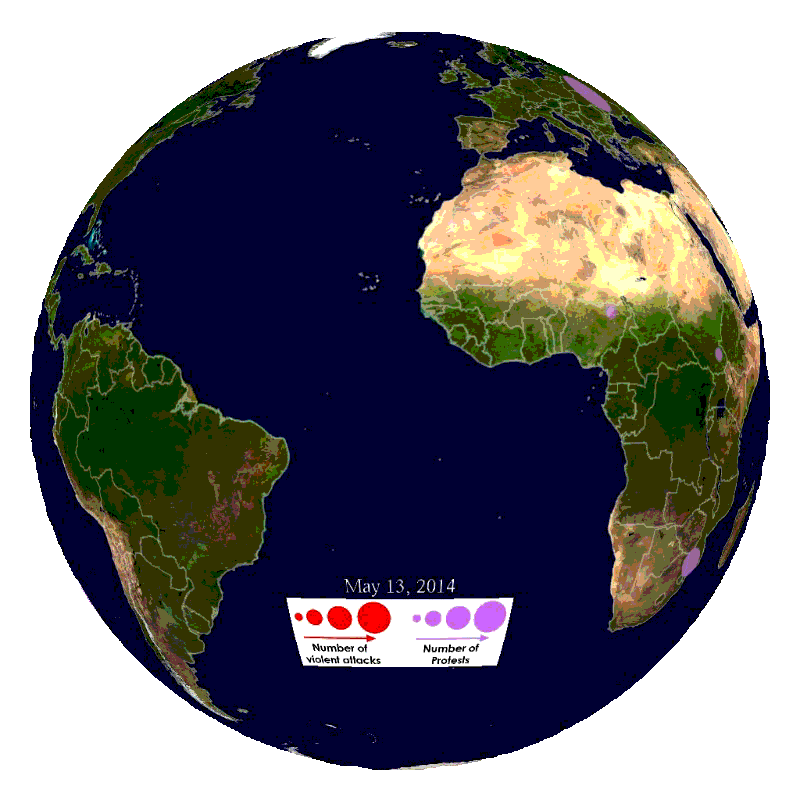
What is GDELT?
GDELT is a service that monitors print, broadcast, and web news media in over 100 languages from nearly all countries in the world. Enabled by this constant stream of news data, GDELT can monitor breaking news events anywhere on the planet. Data scientists and developers can use this data to identify news providers who have a history of generating original content earliest for breaking issues in certain parts of the world, showing you where to look for news when something is happening in your market. Conversely, analysis of GDELT data can show which news providers specialize in redisseminating another provider’s content. In this case, a provider would value pushing out more substantive news to wider audiences at the cost of speed. Finally, as we will demonstrate in this tutorial, GDELT can be used to build event timelines.
GDELT’s Coding System: CAMEO Codes
The CAMEO code is the center of GDELT data analysis. CAMEO, which stands for Conflict and Mediation Event Observations, is a coding framework used to support the study of political and violent events. After passing through a series of extractors and machine learning algorithms, each news story is assigned a CAMEO code, geoinferenced location, and a series of other metadata tags for analysis. As it’s quite possible for a single news story to cover multiple topics (e.g. US President speech on multiple issues), it’s possible for a single news story to have multiple CAMEO codes and GDELT entries. CAMEO codes, along with other parsed values in the GDELT record, can be used to filter and categorize news content. We can subsequently use this filtering pipeline to automatically monitor news at the city, state, or country level on multiple topics across the globe. The coding system is pretty extensive with codes for diplomatic, military, societal, criminal, and economic events or actors. For example, to track all news on mass killings in Kigali, Rwanda, we only need to filter on CAMEO code ‘202’ and the geonames feature identifier (feature ID) for Kigali, ‘-2181358’ .
For all of GDELT’s strengths, it would be intellectually dishonest for me to ignore the reported weaknesses. To see what others have identified as strengths and weaknesses, see M.D. Ward et al’s Comparing GDELT and ICEWS Event Data. One oft cited weakness is duplicates; we’ll introduce a quick fix to reduce duplicates when analyzing a specific CAMEO event code.
Now that we understand GDELT, let’s jump back into the story.
A Killer Neutralized…
Las Vegas responders continued their search for the shooter as the terrifying sound of quick-succesion gunshots engulfed the festival grounds. At least six officers searched Mandalay Bay hotel floor by floor before they found Paddock's room minutes after the shooting started. Paddock, a 64-year old resident of a Mesquite, Nevada retirement community, had apparently rented a two-room suite in the hotel four days before the massacre. As police closed in on his position, Paddock shot and wounded a hotel security officer through the door before Las Vegas Metropolitan Police Department (LVMPD) SWAT used explosives to breach room 32135. Inside, they found Paddock dead. He had killed himself. After 10 minutes of terror that seemed like an eternity, it was finally over.
The barrage from the 32nd floor lasted several minutes but the damage was extensive. Initially, the number of fatalities had climbed to 20. Two hours later, the number had pushed past 50, making it the deadliest active shooter event in recent history. At least two off-duty police officers were shot and killed. Two other police officers were injured, one of them critically. Over 500 people were wounded.

Source: John Locher/AP Photo
Tales of heroism and compassion emerged quickly: Couples held hands as they ran through the dirt lot. Some of the bleeding were carried out by fellow concertgoers. While dozens of ambulances took away the wounded, some people loaded victims into their cars and drove them to the hospital. At least 104 patients were treated at the University Medical Center. Some of the youngest patients treated at the hospital were 16 and 17 years old.
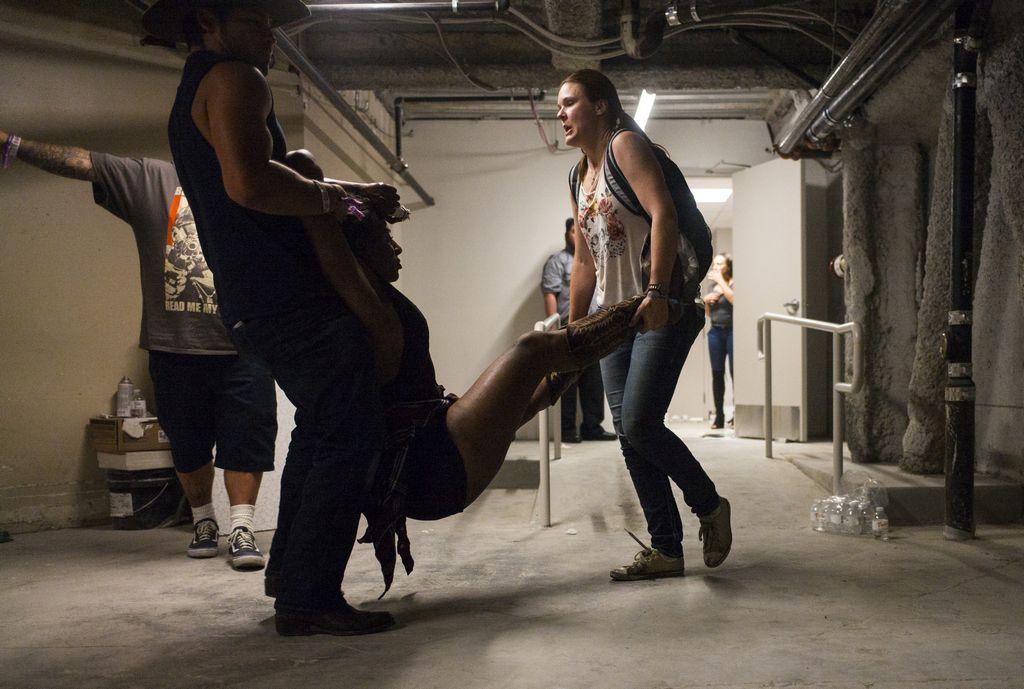
Source: Chase Stevens/Las Vegas Review - Journal via AP
Those who survived physically unscathed did what they could to escape. People fleeing the concert grounds hitched rides with strangers, piling into cars and trucks.
With the shooter neutralized, responders tended to victims and the world searched for an answer to the most difficult question. Why? Why did he do it? A part of that answer would likely come from an answer to another question. Who was Stephen Paddock?
Pythonic Access to Worldwide GeoReferenced News
In the same way that officers relied on training and teamwork to locate the shooter, gdeltPyR and GDELT work in concert to provide access to parsed worldwide news. gdeltPyR is a minimalist Python API for GDELT services and an ideal tool to explore news events that evolve over time. Because of gdeltPyR’s global and multilingual focus, analysis can show how news events spread across the world. For detailed information on the project, visit the gdeltPyR project page on GitHub.
Set up Environment for Code in Tutorial
You can set up the environment to follow this tutorial with a few lines of code. First, make sure you have Anaconda installed. Then, download my environment.yml file, start a terminal session from the directory where the file is downloaded, and type:
conda env create; source activate gdeltblog
That should install all the dependencies.
If you only want to install gdeltPyR, in a terminal session run:
pip install gdelt
Not all current events can be analyzed using gdeltPyR because GDELT is focused on news events that impact security and stability. For examples of the types of events to test, visit the Wikipedia Current Events page and look at the Armed conflicts and attacks or Politics and elections entries. Some examples I’ve tested include:
Outside of making sure your topic is covered in GDELT, gdeltPyR is easy to use and only requires a date when your event of interest occurs. In the future, gdeltPyR will leverage Google’s BigQuery, providing a way to query a specific city, landmark, actor, or CAMEO event code over any amount of time. Additionally, I will be adding a feature to query by specific Local Time or UTC time.
The Las Vegas shooting occurred on October 1, 2017 at 22:08 PDT. GDELT uses UTC datetimes, so this event has a +7 hour difference in GDELT, putting our target timeframe in the early hours of October 2.
Let’s set up the module and libraries:
##############################
# Standard Library
##############################
import datetime
import re
#############################
# Third-party libraries
#############################
from tzwhere import tzwhere
import pandas as pd
import numpy as np
import pytz
#############################
# Local modules
#############################
import gdelt
The tzwhere library can identify the time zone offset using a latitude and longitude pair, so we import this tool for time series functionality later on.
# tzwhere variable for time normalization
tz1 = tzwhere.tzwhere(forceTZ=True)
# instantiate the gdeltPyR object for searches
gd = gdelt.gdelt()
With our libraries set up, let’s get back into the story.
Who was Stephen Paddock?
The search to understand Stephen Paddock started in the room where he died. Police recovered 23 guns (some with scopes) from his room where hotel workers, who were in and out of the room over several days, said they “saw nothing at all” hinting at the forthcoming rampage. At least two of the guns were modified with bump-stock devices which can be attached to the stocks of semiautomatic guns to allow fully automatic gunfire. Investigators could tell from the arsenal, Paddock was intent on killing as many people as possible and the number killed on Oct 1 could have been higher if not for the quick response of the officers. Despite the large arsenal in the room, authorities still had little insight into "why" he did it. Paddock's death meant investigators would be on a scavenger hunt to discover a motive.

In the midst of the hotel room search, officers executed a search warrant at Paddock's three-year-old, 396,000 US dollar two-bedroom home in the tiny desert community of Mesquite, 80 miles north-east of Las Vegas. The discovery included more of the same. They found 19 additional guns, thousands of rounds of ammunition, and explosives. Investigators said they discovered several pounds of ammonium nitrate in his car, a fertilizer that can be used to create explosives.

With the physical search ongoing, officers turned to Paddock's close relationships and life. He had a live-in girlfriend, 62-year-old Marilou Danley, who was traveling in the Philippines when the massacre took place. Although Paddock used some of her identification to check into the hotel, investigators clarified that they believed she was not involved with the shooting. He married Peggy Okamoto in 1985 but the couple divorced in 1990, nearly three decades ago. Peggy, now living in Los Angeles County, California, said she had no contact with him for years.
Financially, Paddock was a wealthy man. He was worth more than $2 million, having made a good chunk of money from buying and selling real estate in several states, including California, Nevada, Florida and Texas. As a retiree, he had no children and plenty of money to play with. So, he took up gambling.
Paddock told neighbors he was a professional gambler and a prospector, and liked to bet big, wagering tens of thousands of dollars in a sitting.
Perhaps Paddock had a checkered past or multiple run-ins with police? Investigators quickly learned this was not the case. A criminal check provided little insight into Paddock’s motive or temperament because he had no criminal record and was not believed to be connected to any militant group. “We have no idea what his belief system was,” Lombardo said. “I can’t get into the mind of a psychopath.”
Next, officers looked into Paddock's arsenal. The paper trail could possibly reveal something. Initial research suggested Paddock had purchased his firearms legally. A Mesquite store, Guns & Guitars, said it sold a gun to Paddock and that “he never gave any indication or reason to believe he was unstable or unfit at any time.” Additional research showed he had purchased multiple firearms in the past, with several of them purchased in California, according to law enforcement officials. Interestingly, those guns didn't appear to be among the 10 or more guns found in the Mandalay Bay hotel room. Nothing materialized from the gun angle.

Source: Getty
Then, the search moved to Paddock's hobbies. He had two planes and held a private pilot's license but had not updated the medical certification required to fly since 2008 or 2010. According to relatives, Paddock liked country music and went to concerts like the Route 91 Harvest festival he attacked on Sunday night.
The look into Paddock's past was proving fruitless. Nothing about Paddock, including his ownership of over 40 guns, seemed out of place or out of the ordinary. Officers decided to move to his family history next. Perhaps his siblings or parents would provide clues.
Using gdeltPyR
Unlike the difficulties investigators experienced in trying to find Paddock’s motive, gdeltPyR is easy to understand and use. As stated earlier, we only need a date and information about the location to find the target data. After we filter the data to the relevant GDELT records, it’s just a “point, click, and read” job because the news stories will be categorized and organized by time.
The code to pull data for October 1 through October 3:
# code to use gdeltPyR; pulling all of 1-3 Oct data (coverage = True)
# and normalizing column names to SQL friendly format (normcols=True)
vegas = gd.Search(
date=['2017 Oct 1','2017 Oct 3'],
coverage=True,
normcols=True
)
Depending on your internet connection, this could take several to tens of seconds to download. My query took 40 seconds to return 461,243 a row by 62 column dataframe that is 996.1 MB. The time (and memory footprint) to download data will be drastically reduced when gdeltPyR includes a direct connection to Google BigQuery. GDELT also ships data out in 15 minute intervals; if you set the coverage parameter to False, it takes 1-2 seconds to return a 2000-3000 row by 62 column dataframe. As GDELT is updated every 15 minutes, a near realtime feed would be easy to manage.
As disscussed earlier, one article can have multiple entries with different CAMEO codes. Our goal is to use the returned metadata to filter down to the relevant records. To see the full details on the columns/metadata, see the schema descriptions here. The most relevant columns for this post are described in the table below:
| Column Name | Description |
|---|---|
| ActionGeo_Lat | field providing the centroid latitude of the landmark for mapping. |
| ActionGeo_Long | field providing the centroid longitude of the landmark for mapping. |
| ActionGeo_FeatureID | field specifies the GNS or GNIS FeatureID for this location. |
| ActionGeo_Type | field specifies the geographic resolution of the match type and holds one of the following values: 1=COUNTRY (match was at the country level), 2=USSTATE (match was to a US state), 3=USCITY (match was to a US city or landmark), 4=WORLDCITY (match was to a city or landmark outside the US), 5=WORLDSTATE (match was to an Administrative Division 1 outside the US – roughly equivalent to a US state). This can be used to filter events by geographic specificity, for example, extracting only those events with a landmark-level geographic resolution for mapping. |
| EventCode | This is the raw CAMEO action code describing the action that Actor1 performed upon Actor2. |
| EventRootCode | This defines the root-level category the CAMEO event code falls under. For example, code “0251” (“Appeal for easing of administrative sanctions”) has a root code of “02” (“Appeal”). This makes it possible to aggregate events at various resolutions of specificity. For events at levels two or one, this field will be set to EventCode. |
| DATEADDED | field provides the date the event was added to the master database in YYYYMMDDHHMMSS format in the UTC time zone. For those needing to access events at 15 minute resolution, this is the field that should be used in queries. |
| SOURCEURL | This field records the URL or citation of the first news report it found this event in. In most cases this is the first report it saw the article in, but due to the timing and flow of news reports through the processing pipeline, this may not always be the very first report, but is at least in the first few reports. |
Note:
gdeltPyRcan normalize columns names into ESRI shapefile friendly strings when thenormcolparameter is set toTrue. So,ActionGeo_Latwould becomeactiongeolat
Each record in the dataframe is a news report in time so we can treat this as a time series. Moreover, GDELT returns data in equally spaced intervals of time which works well for time series analysis.
To condition our data for time series analysis, we will create and use custom functions to make time aware columns that can be used to index our data (e.g. transform UTC to local Pacific Daylight Time using the lat/lon). The code block that follows creates the function and applies it via numpy vectorization. We will also use a chained pandas.DataFrame.assign operation to create our new columns.
def striptimen(x):
"""Strip time from numpy array or list of dates that are integers
Parameters
----------
x : float or int
GDELT date in YYYYMMDDHHmmSS format; sometimes it's a
float others it's an int
Returns
------
datetime obj : obj
Returns a naive python datetime object.
"""
date = str(int(x))
n = np.datetime64("{}-{}-{}T{}:{}:{}".format(
date[:4],date[4:6],date[6:8],date[8:10],date[10:12],date[12:])
)
return n
def timeget(x):
'''convert to datetime object with UTC time tag
Parameters
----------
x : tuple
Tuple containing ordered value of latitude, longitude,
and a datetime object
Returns
------
datetime obj : obj
Returns a time aware python datetime object.
'''
try:
now_aware = pytz.utc.localize(x[2].to_pydatetime())
except:
pass
# get the time zone string representation using lat/lon pair
try:
timezone_str=tz1.tzNameAt(x[0],x[1],forceTZ=True)
# get the time offset
timezone = pytz.timezone(timezone_str)
# convert UTC to calculated local time
aware = now_aware.astimezone(timezone)
return aware
except Exception as e:
pass
# vectorize our function
vect = np.vectorize(striptimen)
# use custom functions to build time enabled columns of dates and zone
vegastimed = (vegas.assign(
dates=vect(vegas.dateadded.values)).assign(
zone=list(timeget(k) for k in vegas.assign(
dates=vect(vegas.dateadded.values))\
[['actiongeolat','actiongeolong','dates']].values)))
The code above created two time-enabled columns; dates and zone. Both columns are datetime64[ns] data types, which means they can be used for time series functionality in pandas. The zone column is a time zone aware data type (Los Angeles time), which adds the time zone offset to UTC time. The dates column is UTC time.
We can filter out any records not related to the Las Vegas shooting using a combination of:
- CAMEO event root codes of 18, 19, and 20 which stand for assault, fight, and engage in unconventional mass violence respectively. See the CAMEO code reference for details on CAMEO event codes. For a higher level of aggregation, consider using the
QuadClassfield as a filter for the GDELT results. - Search for GNIS feature ID representing Las Vegas,847388, in the
actiongeofeatureidfield
Note To get more accurate results, use the GNIS Feature ID for your location filter as opposed to the string representing the location name because some news reports can spell place names differently. A trick to find the feature ID without searching the GeoNames website is to run a
gdeltPyRquery, find a relevant entry, copy the feature ID value, and filter the data using your new value. The feature ID for Las Vegas is 847388. When theActionGeo_Typefield is 3 or 4, understand the feature ID could also be specific and reference a landmark inside a city (stadium, park, building, etc.)
To get help on the fields, reference this headers information file. Finally, we use chained pandas indexing functionality to filter our data in the code block below.
# filter to data in Las Vegas and about violence/fighting/mass murder only
vegastimedfil=(vegastimed[
((vegas.eventrootcode=='19') |
(vegas.eventrootcode=='20') |
(vegas.eventrootcode=='18')) &
(vegas.actiongeofeatureid=='847388')])\
.drop_duplicates('sourceurl')
print(vegastimedfil.shape)
---------------------
Out: (1269, 64)
This operation drastically reduced the size of our data set (from 400,000+ to ~1200). The next step is building the list of chronological news stories. For this post, I manually read stories to extract facts. However, you could leverage information extraction tools combined with entity extractors to build a knowledge base for events of interest. That would be a higher level of analysis and is outside the scope of this post. To build the list of articles, see the code below.
# build the chronological news stories and show the first few rows
print(vegastimedfil.set_index('zone')[['dates','sourceurl']].head())
| dates | sourceurl | |
|---|---|---|
| zone | ||
| 2017-10-01 19:00:00-07:00 | 2017-10-02 02:00:00 | http://www.lasvegasnow.com/news/update-child-f... |
| 2017-10-01 20:00:00-07:00 | 2017-10-02 03:00:00 | https://www.reviewjournal.com/traffic/las-vega... |
| 2017-10-01 23:15:00-07:00 | 2017-10-02 06:15:00 | http://www.dw.com/en/las-vegas-police-active-s... |
| 2017-10-01 23:30:00-07:00 | 2017-10-02 06:30:00 | http://www.goldcoastbulletin.com.au/news/world... |
| 2017-10-01 23:30:00-07:00 | 2017-10-02 06:30:00 | http://www.sanluisobispo.com/news/nation-world... |
Finally, to build a narrative, I read articles chronologically to see how the story unfolded in time. You can look at the url strings to skip irrelevant articles (first 6) or we could use time series analysis to identify a timeframe when the number of news articles with our CAMEO code and in our location of interest increases to an abnormal rate (higher than normal using a running average count).
While reviewing the articles, stay alert. News providers will update information but use the same url. Therefore, some stories will have more information than they had when originally published. GDELT preserves the original time of the article but not the content; you should see clues in the text to let you know the article was updated. Additonally, it’s important to be aware of participation or non-response bias. There may be a news provider who did not have its data processed by GDELT, leading to a faulty conclusion that one particular news provider is faster than another. As always, be wary of data limitations.
If you wanted to index the entire data set for time series analysis, it’s relatively simple because gdeltPyR returns the data in a pandas dataframe. First you would localize the entire dataset to UTC time and then convert it to any time zone offset using the Python time zone string of your choice.
# example of converting to Los Angeles time.
vegastimed.set_index(
vegastimed.dates.astype('datetime64[ns]')
).tz_localize(
'UTC'
).tz_convert(
'America/Los_Angeles'
)
# get time zone string using pytz
Alternatively, you could use the tzwhere library with latitude and longitude to find the time zone string for each GDELT record and normalize time this way. Warning! It is computationally expensive to run this time zone analysis over the entire dataset.
Our data is ready for time series analysis, but first, let’s jump back into the story to see what the police learned about the suspect from family and friends.
Still Seeking a Motive, Investigators Turn to Family and Friends
With little to show from all other leads, investigators hoped family members could provide some answers. At first glance, Stephen Paddock's parental history seemed to provide some clues.
Decades before that fateful Sunday when Stephen perpetrated the worst active shooting event in recent US history, his father was on the FBI’s most-wanted list. Benjamin Hoskins Paddock had been sentenced to 20 years in prison after being convicted of bank robbery and automobile theft. In 1969, when Stephen was 15 years old, Benjamin escaped from prison in El Paso, Texas. He remained on the Most Wanted List from June 10, 1969 until May 5, 1977. He was finally captured in 1978 while running a bingo parlor in Oregon.
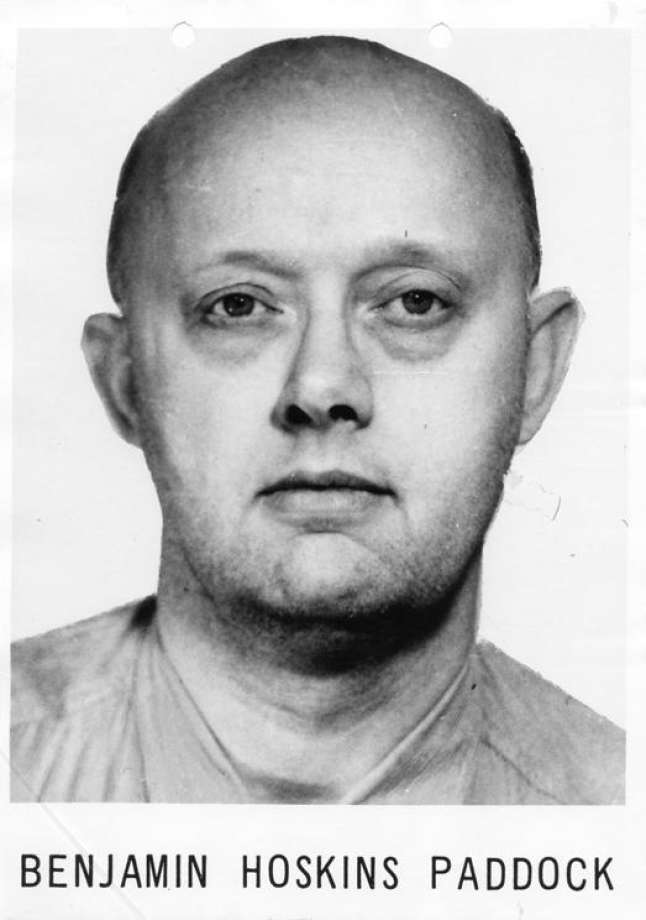
While the paternal history seemed promising, comments by Eric Paddock, Stephen Paddock's brother, suggested the father had little influence in his upbringing.
“I didn’t know him. We didn’t know him,” Eric Paddock said of his paternal father, Benjamin Paddock. “He was never with my mom. I was born on the run and that’s the last time he was ever associated with by our family.”
Another dead end.
As the only family member speaking publicly, Eric answered questions on his brother's frame of mind, which only raised more questions as to why Stephen picked up the gun that Sunday night. His answers didn't get us any closer to a motive.

"We have absolutely no idea whatsoever," Eric Paddock said to reporters gathered outside his home Monday morning. "We have no idea why he did this. And that's what you're going to find out. I can't imagine. When you guys found out why this happened, let us know. I have no idea whatsoever."
The response seemed totally out of touch with the man who used his modified rifles to kill 50 and wound over 500 innocent people. Even more troubling, was the brother's comments on his brother's ownership of guns. He said Stephen was, “Not an avid gun guy at all...where the hell did he get automatic weapons? He has no military background." But, as it turns out, Stephen had a lot of guns. More importantly, he had guns that suggested an affinity and interest that surpassed those of a "casual" gun owner.

Statements from Paddock's live-in girlfriend were contradictory as well when compared to his actions. Everyone painted Paddock as a guy who kept to himself. They all seem genuinely surprised.
"I knew Stephen Paddock as a kind, caring, quiet man," Marilou Danley said in a statement read by her attorney. "He never said anything to me or took any action that I was aware of that I understood in any way to be a warning that something horrible like this would happen.”

It seemed that no one truly knew Stephen Paddock. Or perhaps the Paddock who fired the gun on thousands of helpless people was the imposter; perhaps he snapped that day. Either way, there was no conclusive evidence.
Investigation Continues but Questions Remain
Family and friend interviews answered questions about Stephen Paddock the person. But they did not answer questions about Paddock the gunman. Overall, investigators did an admirable job piecing together the timeline of events and gathering background on the shooter. They had information on the shooter's life, friends, financial situation, family history, and insight into where he purchased the guns.
As the aftermath of the Las Vegas event settles, the world struggles to come to terms with what happened. Each person or group affected has something to cope with: families mourn those who died, the injured begin the healing process, people close to Stephen question if they ever really knew him, survivors confront the reality of their escape from death or maiming, and everyone struggles to make sense of the whole ordeal. The timeline of events is somewhat clear, but one glaring question remains.
Why?
Why did Stephen Paddock bring all those guns to his room? Why did he snap that day? Why did he go on to commit the worst active shooter massacre in recent US history?
Only time will tell.
Or worse. Perhaps we will never know.
The Data Science Detour: Analyzing GDELT data
Our narrative ended with a lot of unanswered questions about Paddock, but our code tutorial answered several questions regarding gdeltPyR and GDELT. We learned GDELT is a service that monitors print, broadcast, and web news media all over the world in over 100 languages. We also learned the gdeltPyR library provides a Pythonic pathway to query GDELT’s parsed news data. Then, we used gdeltPyR to get a tidy, time-enabled data set about the Las Vegas active shooter event, which provided enough information to see the story evolve. As stated, my example is trivial and focused on a U.S. problem; we could have easily picked a similar event in some remote part of the world, tracking news stories in any one of 100 languages, and had similar results.
Up until now, our coding was utilitarian in nature; it was focused on defining and downloading the GDELT data we wanted. To cross into the realm of data science, we need to extract knowledge or insights from our GDELT data that could drive a decision. In data science, the goal is to create a data product. Data products derive their value from data and generate more data by influencing human behavior or by making inferences or predictions upon new data. In this section, we use GDELT data to answer questions where the answers could be used to drive human or business decisions for a client who was interested in finding the most responsive and reliable news provider for a specific city.
While reading, feel free to pause and try your solution before continuing to my solution. These are simple questions so give it a try.
Question 1: Who Produced the Most Articles About the Las Vegas Active Shooter Event?
With the analytic power of Python pandas and regex, we can identify the news source with the highest original production (unique urls). As stated early on, one problem with GDELT is duplicates. A parsed news article can have multiple entries that use the exact same url. Moreover, the urls are unique in that they point to specific articles. We can use regex to strip the root URL from each record and then count occurrences. I wrote some regex to accomplish both. Again, we use chained operations to get our desired output in one line of code.
import re
import pandas as pd
# regex to strip a url from a string; should work on any url (let me know if it doesn't)
s = re.compile('(http://|https://)([A-Za-z0-9_\.-]+)')
# apply regex to each url; strip provider; assign as new column
print(vegastimedfil.assign(provider=vegastimedfil.sourceurl.\
apply(lambda x: s.search(x).group() if s.search(x) else np.nan))\
i.groupby(['provider']).size().sort_values(ascending=False).reset_index().rename(columns={0:"count"}).head())
| provider | count | |
|---|---|---|
| 0 | https://www.yahoo.com | 25 |
| 1 | https://www.reviewjournal.com | 15 |
| 2 | https://article.wn.com | 14 |
| 3 | https://patch.com | 11 |
| 4 | http://www.msn.com | 9 |
After some research into the top URLs, you’ll find https://www.reviewjournal.com is an interesting top producer with 15 stories. The other sites are world wide generic sites that likley have syndicated reporting. But https://www.reviewjournal.com is different. A visit to the site and close look at the top left banner provides all the information we need.
After visiting the site, we see the name is the Las Vegas Review Journal, which explains a lot. This is a local paper, meaning this provider is more likely to have reporters on the ground to keep its viewership/readership informed of breaking information.
How can this information help drive decisions? While anecdotal, we used analytics to identify a local news provider to keep track of major events in a city. This could be repeated for the same city to get a more statistically relevant conclusion. Moreover, this analytic could be repeated for other cities to find the local papers/providers for each city of interest. With this information, it’s possible to keep a tab on local events and how the local population perceives the events. This output focused on individual production, but what about looking at how many different producers covered the story in our time frame. That leads to our next question.
Question 2: How many unique news providers did we have producing on the the Las Vegas Active Shooter Event?
The purpose of answering this question is to see just how wide GDELT’s coverage is; does GDELT have a few sources publishing multiple stories or are multiple sources publishing a few stories? This question is easy to answer because of the work we did in the previous question. Each base url counts as a unique news provider (e.g. https://www.reviewjournal.com). GDELT gave us a tidy data set, so we just count up the occurrences.
# chained operation to return shape
vegastimedfil.assign(provider=vegastimedfil.sourceurl.\
apply(lambda x: s.search(x).group() if \
s.search(x) else np.nan))['provider']\
.value_counts().shape
---------------------
Out: (797,)
GDELT pulled from 797 news sources for this Las Vegas active shooter story alone; that’s out of ~1200 stories. Imagine how many providers exist for the entire day for all geographic regions and CAMEO codes?
This provides some evidence of GDELT’s wide reaching sources. Looking at the distribution plots below, we see that most news providers wrote less than 5 news stories, with most only producing between 1 and 2 stories. If a news provider produced 4 articles, they were in the 95th percentile. So, all producers above this number can be considered high producers, and with the Las Vegas Review being a local paper, that’s pretty impressive to be in the top 5 with global producers like Yahoo, World News, Patch, and MSN. If we were advising our clients on which news sources to use for the security situation in Las Vegas, we have a data-based reason to recommend the Review Journal over other local providers. Of course, additional tests would make the recommendation stronger.
These recommendations are based on GDELT processed news and not raw parsing of all news. It’s always good practice to caveat the limitations of the data and recommendations that come from your analysis of the data.
Here is the distribution plot.
import matplotlib.pyplot as plt
import seaborn as sns
# make plot canvas
f,ax = plt.subplots(figsize=(15,5))
# set title
plt.title('Distributions of Las Vegas Active Shooter News Production')
# ckernel density plot
sns.kdeplot(vegastimedfil.assign(provider=vegastimedfil.sourceurl.\
apply(lambda x: s.search(x).group() if s.search(x) else np.nan))['provider']\
.value_counts(),bw=0.4,shade=True,label='No. of articles written',ax=ax)
# cumulative distribution plot
sns.kdeplot(vegastimedfil.assign(provider=vegastimedfil.sourceurl.\
apply(lambda x: s.search(x).group() if s.search(x) else np.nan))['provider']\
.value_counts(),bw=0.4,shade=True,label='Cumulative',cumulative=True,ax=ax)
# show it
plt.show()
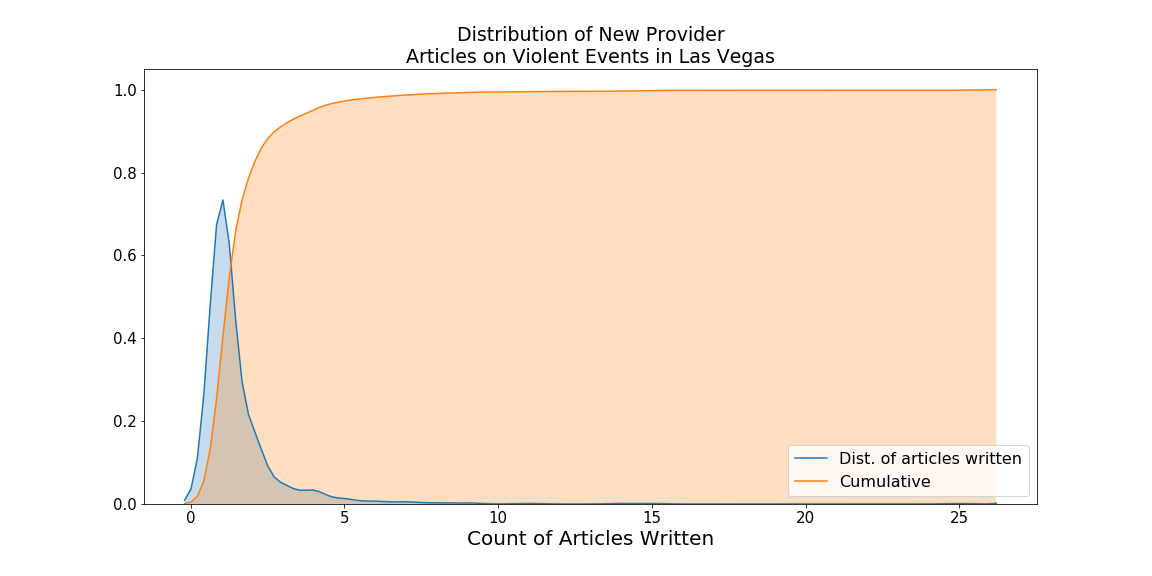
A good number of new sources only published one or two stories; this could be for a number of reasons. Those producers who don’t have many viewers/readers in Vegas may provide an initial report from a syndicated partner or a precursory update for a national/global audience. In another scenario, national/global providers may wait to establish a local presence before increasing coverage. The latter suggests we should expect to see a gradual rise in the number of published reports as more reporters get in place. That leads to our next series of questions, where our answers leverage time series analysis concepts.
Question 3: What changes did we see in the volume of news reports about the Las Vegas active shooter event?
Time series is where GDELT data shines. GDELT processes data in equally spaced intervals (15 minutes), and we can use an exponentially weighted moving average to look at the volumetric change. To improve the validity of the results, we will normalize the count of Las Vegas active shooter news stories in GDELT to the count of all news stories for each 15 minute interval. As a result, we will see our monitored value as a proporation as opposed to a raw count. For example:
- 1000 total GDELT events for one 15 minute interval
- 100 total events in our CAMEO code of interest for the same 15 minute interval
- We would just divide 100/1000 to get our normalized value for the 15 minute interval
Our data is time indexed to Los Angeles time. Again, I’m using chained pandas operations to simplify the code to fewer lines. Here is the code and plot.
import matplotlib.pyplot as plt
timeseries = pd.concat([vegastimed.set_index(vegastimed.dates.astype('datetime64[ns]')).tz_localize('UTC').tz_convert('America/Los_Angeles').resample('15T')['sourceurl'].count(),vegastimedfil.set_index('zone').resample('15T')['sourceurl'].count()]
,axis=1)
# file empty event counts with zero
timeseries.fillna(0,inplace=True)
# rename columns
timeseries.columns = ['Total Events','Las Vegas Events Only']
# combine
timeseries = timeseries.assign(Normalized=(timeseries['Las Vegas Events Only']/timeseries['Total Events'])*100)
# make the plot
f,ax = plt.subplots(figsize=(13,7))
ax = timeseries.Normalized.ewm(adjust=True,ignore_na=True,min_periods=10,span=20).mean().plot(color="#C10534",label='Exponentially Weighted Count')
ax.set_title('Reports of Violent Events Per 15 Minutes in Vegas',fontsize=28)
for label in ax.get_xticklabels():
label.set_fontsize(16)
ax.set_xlabel('Hour of the Day', fontsize=20)
ax.set_ylabel('Percentage of Hourly Total',fontsize='15')
ax.legend()
plt.tight_layout()
plt.show()
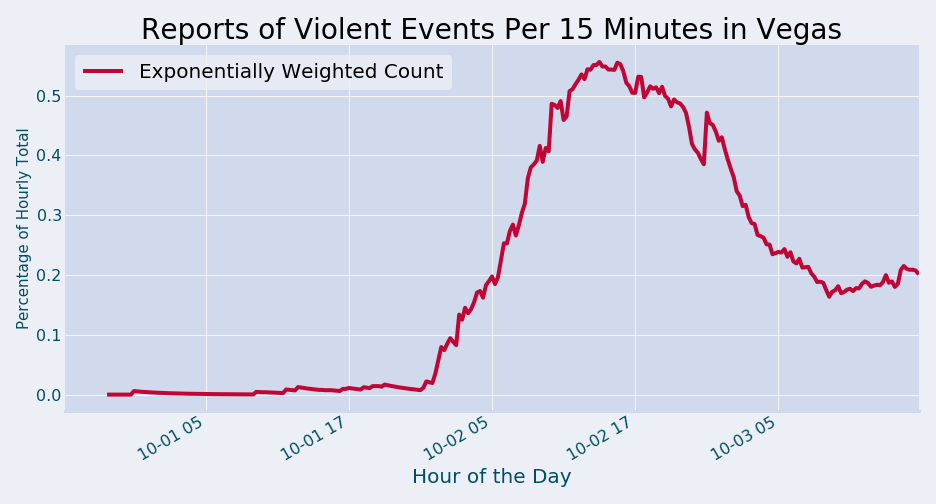
As we noted early on in this post, GDELT automatically geolocated this news event to Las Vegas within 1 hour of the gunshots being fired. While it’s true that breaking news and television stations were reporting the story within minutes, it’s important to note that GDELT automatically inferred the location, CAMEO code, and actors. If we established automated pipelines for multiple locations similar to what we implemented in this post, gdeltPyR and GDELT can be a force multiplier when human capital and time are constraining factors.
Speaking of time, we can answer another temporal question regarding the “fastest” producer.
Question 4: Using the GDELT processed news providers as the population, which provider produced the fastest overall?
This question can be tricky, but we have all the data needed to answer the question. We want to calculate, on average, which news provider gets stories out faster. In a business case, the answer to this question would support the recommendations we made earlier, giving our client an added dimension to not just track the news provider who produces the most content, but also the provider who is fastest on the scene when a breaking event happens.
To get an average time, we need time as an integer (epoch). The bulk of this computation will focus on converting to epoch. We are getting slightly more advanced in our wrangling/computation. The steps are:
- Group data by news source
- Filter data and only keep sources that provided 3 or more original news stories
- Compute summary statistics (mean, max, min) over our epoch timestamps for each provider
- Convert epoch time to human readable datetime
- Sort the final results; provider with earliest average listed first
- Localize the time to UTC
- Convert the time from UTC to Philippines time
- Rename columns
- Rename index
Here is the code:
# complex, chained operations to perform all steps listed above
print((((vegastimedfil.reset_index().assign(provider=vegastimedfil.reset_index().sourceurl.\
apply(lambda x: s.search(x).group() if s.search(x) else np.nan),\
epochzone=vegastimedfil.set_index('dates')\
.reset_index()['dates']\
.apply(lambda x: (x.to_pydatetime().timestamp()))).groupby('provider')\
.filter(lambda x: len(x)>=10).groupby('provider').agg([np.mean,np.max,np.min,np.median])\
.sort_index(level='median',ascending=False)['epochzone']['median'])\
.apply(lambda x:datetime.datetime.fromtimestamp(int(x)))\
.sort_values(ascending=True)).reset_index()\
.set_index('median',drop=False)).tz_localize('UTC')\
.tz_convert('America/Los_Angeles'))
| provider | median | |
|---|---|---|
| median | ||
| 2017-10-02 15:45:00-07:00 | https://www.reviewjournal.com | 2017-10-02 22:45:00 |
| 2017-10-02 18:15:00-07:00 | https://www.yahoo.com | 2017-10-03 01:15:00 |
| 2017-10-02 19:45:00-07:00 | https://article.wn.com | 2017-10-03 02:45:00 |
| 2017-10-03 08:00:00-07:00 | https://patch.com | 2017-10-03 15:00:00 |
It comes as no surprise that the local paper, the Las Vegas Review Journal, is the fastest overall producer on this topic when we consider new producers who produced a minimum of 10 articles. Returning to our ficticious business customer, we have more ammunition for our data-based recommendation to follow the Las Vegas Review Journal for violent event coverage in Las Vegas. We would of course need to test this scenario on other high profile events, but we have some preliminary information to have discussions with our customer.
We will close this post with a challenge to answer the most difficult question.
The Data Scientist Challenge
Question 5: Who produces the most semantically dissimilar content?
By answering this question, and combining with all the answers from above, we could more confidently recommend a local news source to our client because we would have identified:
- who produces the most
- who produces the fastest
- who produces the most unique content
Note Every recommendation/classification above is caveated with “according to GDELT parsed news feeds”. And, we would need more examples to increase the relevance of the recommendation
In totality, these answers identify the producer who is always getting the scoop on a story using a repeatable data-driven approach. While this challenge posits the most difficult question, the tools/libraries that you can use are well known. Consider using scikit-learn, gensim (semantic similarity), and nltk (Levenshtein edit distance), etc.
The first step to answer Question 5 is getting the content, and I’ll provide the code for you.
The function to scrape content works surprisingly on from MOST news websites and strips away a lot of junk. For those websites where it doesn’t work (blocked, IP issues, etc.), I added exceptions and warnings to give as much information as possible. Here is the code from my GitHub gist:
I will provide an example of using the code. When building text corpora in Python, remember to yield instead of return in your function. yield leads to a lazy (on demand) generation of values, which translates to lower memory usage. This code stores the returned data in memory but could easily be modified to write to disk.
# create vectorized function
vect = np.vectorize(textgetter)
#vectorize the operation
cc = vect(vegastimedfil['sourceurl'].values[10:25])
#Vectorized opp
dd = list(next(l) for l in cc)
# the output
pd.DataFrame(dd).head(5)
| base | text | title | |
|---|---|---|---|
| 0 | http://www.goldcoastbulletin.com.au | Automatic gunfire at the Mandalay Bay Resort i... | Las Vegas shooter: Mandalay Bay casino gunman ... |
| 1 | http://www.sanluisobispo.com | Unable to reach website. | |
| 2 | http://www.nydailynews.com | \r\n\tA lone shooter rained death along the La... | Mass shooting at Mandalay Bay concert in Las V... |
| 3 | http://www.hindustantimes.com | A gunman opened fire at a country music festiv... | Las Vegas shooting: Over 20 dead, 100 injured;... |
| 4 | https://www.themorningbulletin.com.au | \n\tLAS Vegas shooter Stephen Paddock had a st... | Las Vegas shooting: Gunman Stephen Paddock had... |
You have all the data to complete the challenge! Thanks for reading! I’m curious to see how you tackle this problem. Please share!